TEXTBEFORE関数の引数
| 引数 | 意味 | |
| text 文字列 |
必須 | 検索対象のテキスト |
| delimiter 区切り文字 |
必須 | 抽出する前のポイントをマークするテキスト 区切り文字 |
| instance_num 区切り位置 |
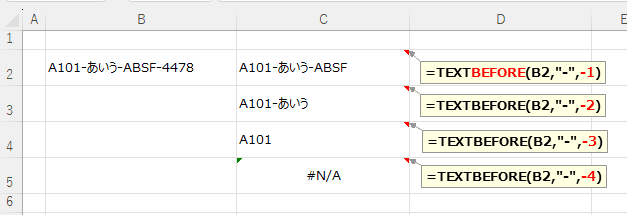
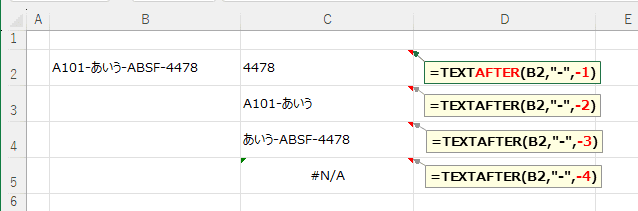
省略可 | 区切り文字が複数ある時、前からの順番 既定では、instance_num = 1 です。 負の数を指定すると、テキストの末尾から検索が開始します。 |
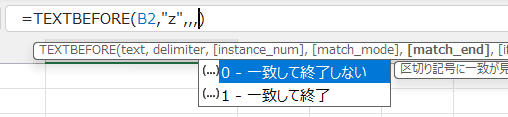
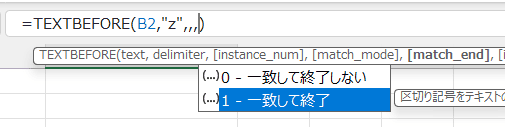
| match_mode 一致モード |
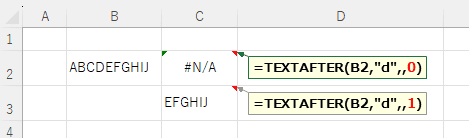
省略可 | テキスト検索で大文字と小文字を区別するかどうかを決定します 0または省略:大文字と小文字を区別します。 1:大文字と小文字を区別しません |
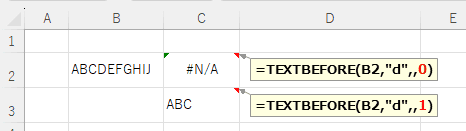
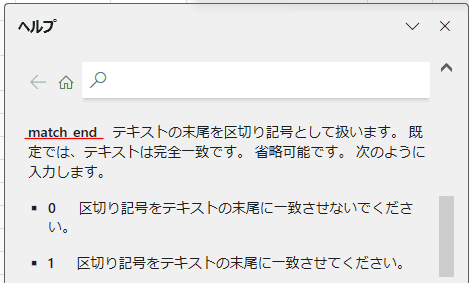
| match_end 末端で一致する |
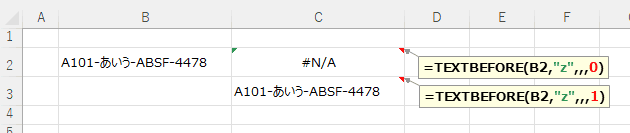
省略可 | テキストの末尾を区切り記号として扱います 0または省略:一致して終了しない 1:一致して終了 |
| if_not_found 見つからないとき |
省略可 | 一致するものが見つからない場合に返される値。 既定では、#N/A が返されます |
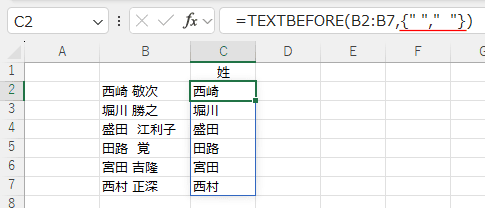
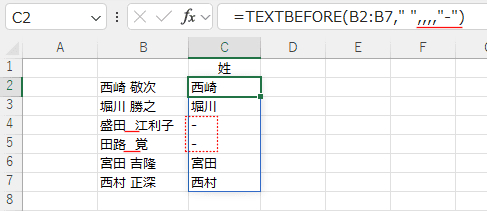
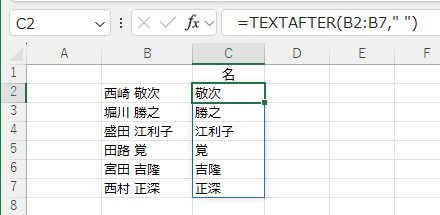
区切り文字に " "(半角のスペース)を設定して、半角スペースより前の文字列を取り出します。
C2セルに =TEXTBEFORE(B2:B7," ") と入力します。
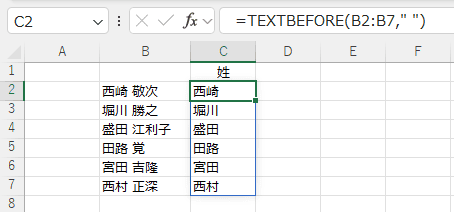
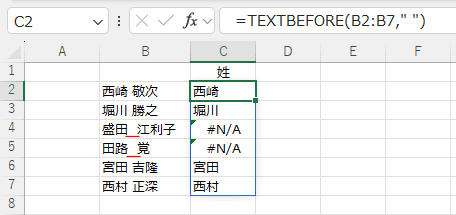
=TEXTBEFORE(B2:B7," ") では 半角のスペースを区切り文字に設定しています。
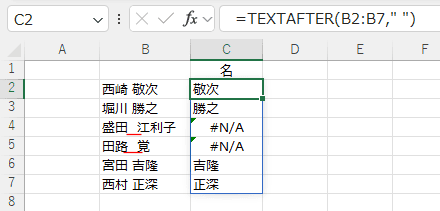
半角のスペースがない文字列(4行目と5行目)ではエラー #N/A が返されます。
↓
=TEXTBEFORE(B2:B7,{" "," "}) と全角スペースも併せて指定することができます。