- Home »
- エクセル関数一覧表 »
- Excel関数の目次 »
- PIVOTBY関数でクロス集計表を作る
- PIVOTBY関数が Excel for Microsoft365 で使用できるようになりました。
このページではPIVOTBY関数の使い方を詳細に説明しています。
引数の使い方も詳細に説明し、応用的な使い方も解説しています。
- この新関数のみで、行と列のデータのクロス集計ができるようになりました。
従来は複数の関数を組み合わせて作成したり、ピボットテーブルで作成していたものがこのPIVOTBY関数でできます。
引数が横文字だったりしてちょっとわかりにくいところもありますが、今後改善されることを期待しています。
列のグループ化で集計する場合は GROUPBY関数が使えます。
更新:2024/12/05;作成:2024/10/29
行と列のクロス集計ができます
ピボット バイ
=PIVOTBY(row_fields,col_fields,values,function,
[field_headers],[row_total_depth],[row_sort_order],
[col_total_depth],[col_sort_order],[filter_array],[relative_to])
- PIVOTBY関数がExcel for Microsoft 365 で使用することができるようになりました。(2024/10/29に確認しました)
バージョン 2409 (ビルド 18025.20096),バージョン 2409: 9 月 23 日から使用できるようになったようです。
- ここの数式をトレースできるように使用したデータをリストにしておきますので、ご利用ください。
| |
B |
C |
D |
E |
F |
G |
| 3 |
番号 |
氏名 |
年齢 |
性別 |
血液型 |
得点 |
| 4 |
1 |
上原嘉男 |
44 |
男 |
O |
91 |
| 5 |
2 |
森永彩芽 |
58 |
女 |
A |
98 |
| 6 |
3 |
古田恵 |
41 |
女 |
AB |
61 |
| 7 |
4 |
太田千恵子 |
34 |
女 |
B |
46 |
| 8 |
5 |
豊田啓一 |
38 |
男 |
O |
78 |
| 9 |
6 |
新村遥奈 |
29 |
女 |
A |
76 |
| 10 |
7 |
坂元彩香 |
38 |
女 |
AB |
68 |
| 11 |
8 |
坪井尚生 |
45 |
男 |
A |
77 |
| 12 |
9 |
西原舞 |
47 |
女 |
B |
41 |
| 13 |
10 |
中野野乃花 |
51 |
女 |
O |
93 |
| 14 |
11 |
岩渕佳代 |
44 |
女 |
A |
61 |
| 15 |
12 |
市村将文 |
58 |
男 |
AB |
66 |
| 16 |
13 |
芦田公平 |
59 |
男 |
A |
90 |
| 17 |
14 |
高見美姫 |
34 |
女 |
AB |
81 |
| 18 |
15 |
高山晴彦 |
65 |
男 |
B |
76 |
| 19 |
16 |
高島嘉子 |
53 |
女 |
A |
85 |
| 20 |
17 |
蛭田功一 |
46 |
男 |
O |
60 |
| 21 |
18 |
北奈那 |
42 |
女 |
B |
84 |
| 22 |
19 |
本田明莉 |
62 |
女 |
A |
66 |
| 23 |
20 |
東海林真依 |
63 |
女 |
AB |
92 |
- PIVOTBY関数の引数(現時点では英語表記になっています。)
| 引数 |
|
意味 |
| row_fields |
必須 |
行のデータ |
| col_fields |
必須 |
列のデータ |
| values |
必須 |
値 |
| function |
必須 |
関数 |
| field_headers |
省略可 |
ヘッダーの表示方法 |
| row_total_depth |
省略可 |
行の合計の表示方法 |
| row_sort_order |
省略可 |
行の並べ替え |
| col_total_depth |
省略可 |
列の合計の表示方法 |
| col_sort_order |
省略可 |
列の並べ替え |
| filter_array |
省略可 |
フィルター |
| field_relationship |
省略可 |
リレーション |
- イータ縮小ラムダ関数で指定します。明示的なLAMBDA関数で指定することもできます。
イータ縮小ラムダ関数「SUM」は、LAMBDA(x,SUM(x)) というLAMBDA関数式の簡略版です。
Helpには下表のように記されています。
値の集計に使用される、明示的または eta の縮小ラムダ (SUM、PERCENTOF、AVERAGE、COUNT など)。
ラムダのベクトルを指定できます。 その場合、出力には複数の集計が含まれます。 ベクターの向きによって、行方向と列方向のどちらをレイアウトするかが決まります。 |
SUBTOTAL関数のように数値で指定しません。またいくつかの関数が選択肢に増えています。
(PERCENTOF、ARRAYTOTEXT、MODE.SNGL、LAMBDA)
| イータ縮小ラムダ関数 |
意味 |
| SUM |
合計値 |
| PERCENTOF |
構成比率 |
| AVERAGE |
平均値 |
| MEDIAN |
中央値 |
| COUNT |
値の件数 |
| COUNTA |
全ての件数 |
| MAX |
最大値 |
| MIN |
最小値 |
| PRODUCT |
掛けた値 |
| ARRAYTOTEXT |
文字を区切り文字付で結合する |
| CONCAT |
文字を結合する |
| STDEV.S |
標準偏差(標本) |
| STDEV.P |
標準偏差(母集団全体) |
| VAR.S |
分散(標本) |
| VAR,P |
分散(母集団全体) |
| MODE.SNGL |
最頻値 |
| LAMBDA |
任意の計算方法 |
- field_headers:ヘッダーの表示方法
| 引数 |
意味 |
| 0 |
フィールドにフィールド名がないので、表示しない |
| 1 |
フィールドにフィールド名が含まれているが、表示しません |
| 2 |
フィールドにフィールド名がないので、生成しない?
(実際は、Excelが勝手にヘッダーを表示します) |
| 3 |
フィールドにフィールド名が含まれているので、表示します |
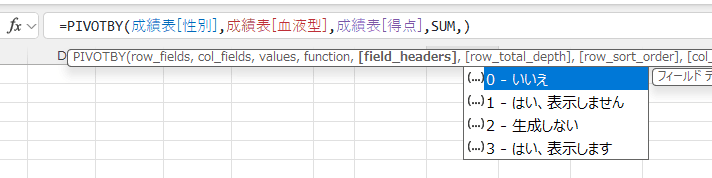
- テーブルでfield_headers:ヘッダーの表示方法を指定した場合は下図のようになります。
引数が0と1の場合は同じようになっています。
引数が2と3の場合はちょっと邪魔なところが見られます。
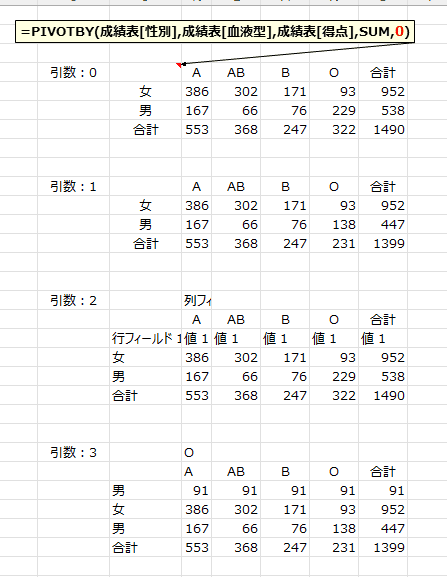
- セル範囲にフィールド行を含めていない場合と、フィールド行を含めている場合でヘッダーの表示が変わります。
いろいろケースバイケースで試す必要がありそうです。
フィールド行を含めていない場合は引数を0と1が使えそうな気がします。
フィールド行を含めている場合は引数を1が使えそうな気がします。
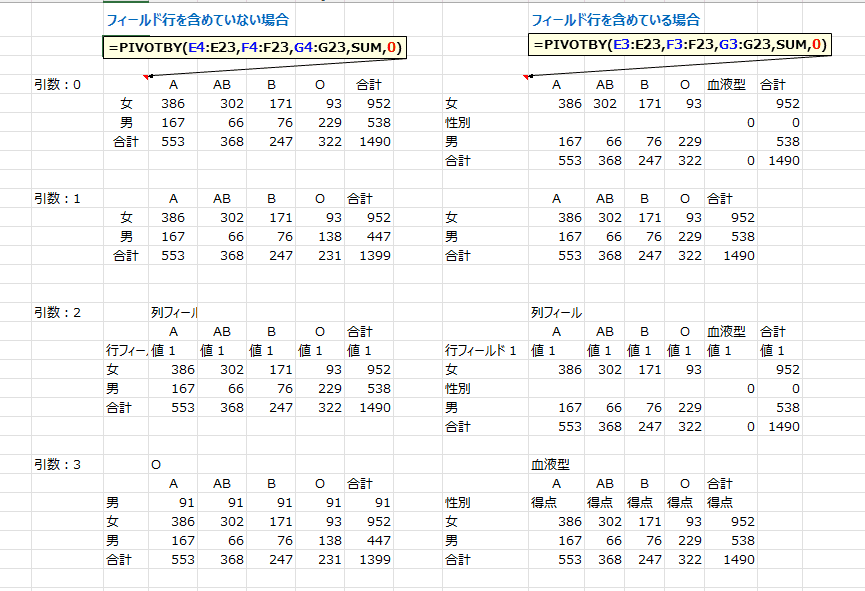
- row_total_depth:行の合計の表示方法
| 引数 |
意味 |
| 0 |
合計なし |
| 1 |
総計 |
| 2 |
総計と小計 |
| -1 |
上部に総計 |
| -2 |
上部に総計と小計 |
なお、省略した場合は総計と、可能な場合は小計が表示されます。
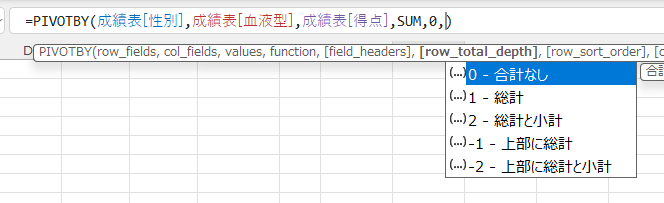
- 血液型と性別ごとに得点が合計されています。データは「成績表」というテーブルに変換しています。
UNIQE関数やSUMIFS関数での計算が一気にできた感じです。
=PIVOTBY(成績表[性別],成績表[血液型],成績表[得点],SUM,0,0)
- 引数の行の合計の表示方法の指定によってはエラーとなる場合もあります。
下図のような場合は、引数は0と1と-1が利用できそうです。

row_sort_order:行の並べ替え
- row_sort_order:行の並べ替え
フィールドの昇順/降順に並べ替えられます。
列の位置を指定し、正の数は昇順、負の値は降順に並べ替えます。
- 引数の行の並べ替えに1,-1,2,-2を指定した例です。

col_total_depth:列の合計の表示方法
- col_total_depth:列の合計の表示方法
省略した場合は総計と、可能な場合は小計が表示されます。
ここでは 0 としましたので、列の合計は表示されません。
- col_sort_order:列の並べ替え
フィールドの昇順/降順に並べ替えられます。
- =PIVOTBY(成績表[性別],成績表[血液型],成績表[得点],SUM,0,0,,0,-1)
ここでは -1 と負の値を指定していますので、列フィールド”性別"が降順に並べ替えられます。
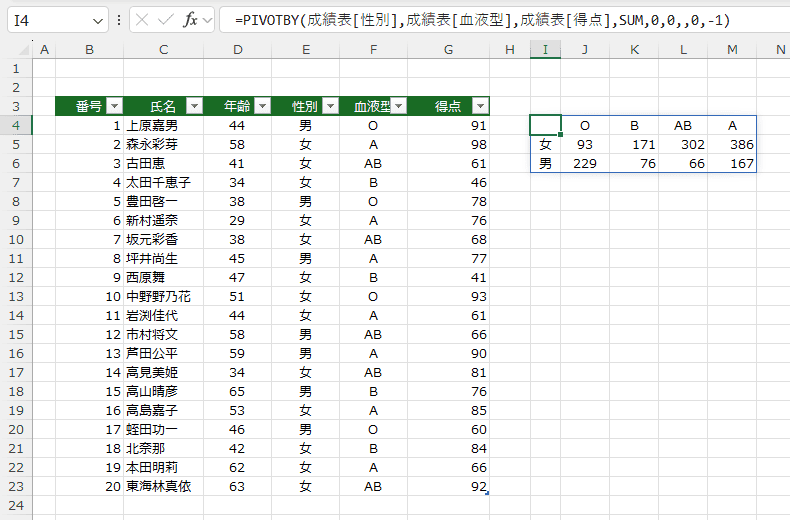
- フィルターする条件を入力します。
- データをフィルターして計算します。
=PIVOTBY(成績表[性別],成績表[血液型],成績表[得点],SUM,0,0,,0,,成績表[性別]="男")
成績表[性別]="男" のデータだけが表示されました。
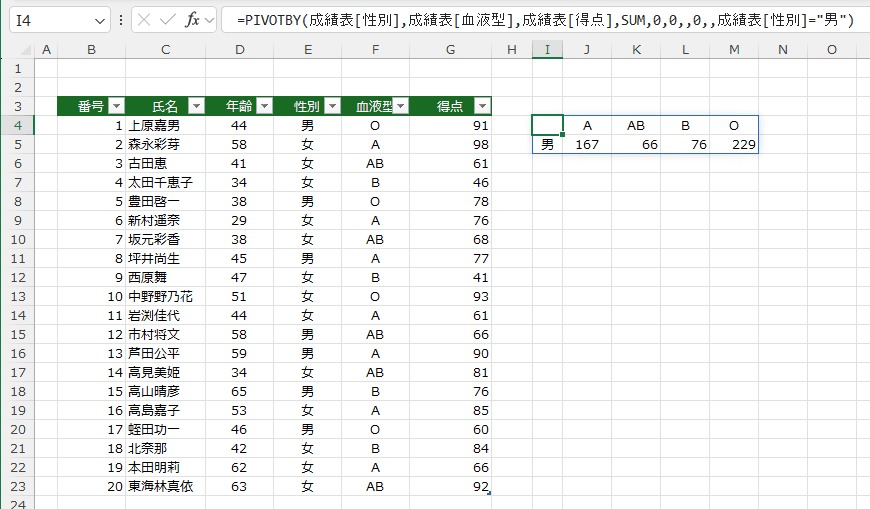
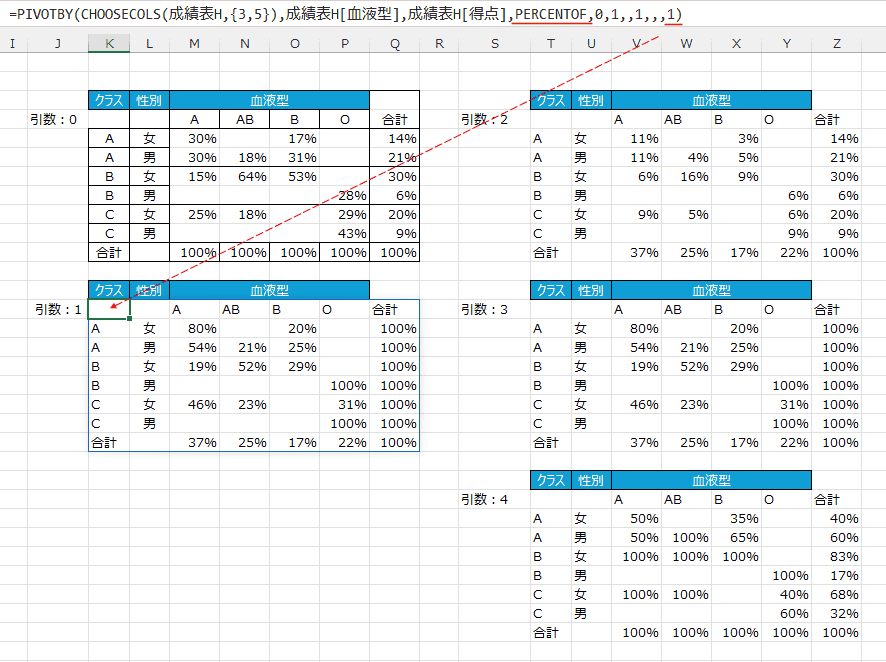
- field_relationship:リレーション
0〜4の選択肢があるのがわかります。
| 0 |
列の合計(既定) |
| 1 |
行の合計 |
| 2 |
総計 |
| 3 |
親列の合計 |
| 4 |
親列集計 |

- 計算方法をPERCENTOFにすると違いが判るようです。
引数を0〜4に変えた時の違いを下図に示しています。
- D列に「クラス」を追加しました。テーブルの名前は「成績表H」としています。
ここでは、このデータを使います。
|
B |
C |
D |
E |
F |
G |
H |
| 3 |
番号 |
氏名 |
クラス |
年齢 |
性別 |
血液型 |
得点 |
| 4 |
1 |
上原嘉男 |
B |
44 |
男 |
O |
91 |
| 5 |
2 |
森永彩芽 |
A |
58 |
女 |
A |
98 |
| 6 |
3 |
古田恵 |
B |
41 |
女 |
AB |
61 |
| 7 |
4 |
太田千恵子 |
B |
34 |
女 |
B |
46 |
| 8 |
5 |
豊田啓一 |
C |
38 |
男 |
O |
78 |
| 9 |
6 |
新村遥奈 |
C |
29 |
女 |
A |
76 |
| 10 |
7 |
坂元彩香 |
C |
38 |
女 |
AB |
68 |
| 11 |
8 |
坪井尚生 |
A |
45 |
男 |
A |
77 |
| 12 |
9 |
西原舞 |
A |
47 |
女 |
B |
41 |
| 13 |
10 |
中野野乃花 |
C |
51 |
女 |
O |
93 |
| 14 |
11 |
岩渕佳代 |
C |
44 |
女 |
A |
61 |
| 15 |
12 |
市村将文 |
A |
58 |
男 |
AB |
66 |
| 16 |
13 |
芦田公平 |
A |
59 |
男 |
A |
90 |
| 17 |
14 |
高見美姫 |
B |
34 |
女 |
AB |
81 |
| 18 |
15 |
高山晴彦 |
A |
65 |
男 |
B |
76 |
| 19 |
16 |
高島嘉子 |
B |
53 |
女 |
A |
85 |
| 20 |
17 |
蛭田功一 |
C |
46 |
男 |
O |
60 |
| 21 |
18 |
北奈那 |
B |
42 |
女 |
B |
84 |
| 22 |
19 |
本田明莉 |
A |
62 |
女 |
A |
66 |
| 23 |
20 |
東海林真依 |
B |
63 |
女 |
AB |
92 |
- 2列のデータを利用してみます。
まずは、HSTACK関数を使ってみます。
=PIVOTBY(HSTACK(成績表H[クラス],成績表H[性別]),成績表H[血液型],成績表H[得点],SUM,0,1,,1,,,0)
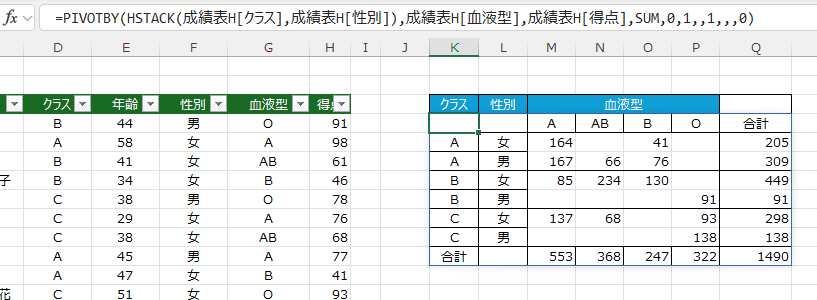
- CHOOSECOLS関数を使っても同様な結果になりました。
=PIVOTBY(CHOOSECOLS(成績表H,{3,5}),成績表H[血液型],成績表H[得点],SUM,0,1,,1,,,0)
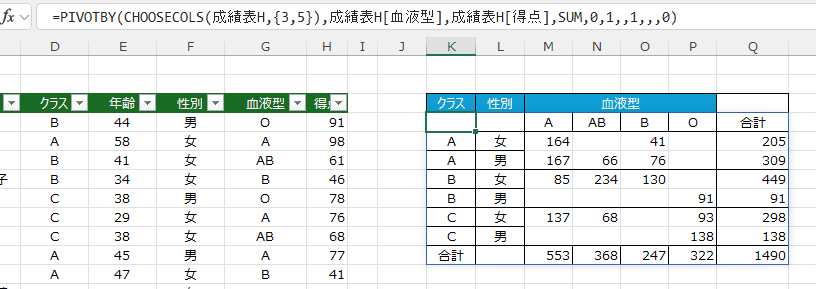
- ここではフィールド名を表示するのに都合がよかったので、テーブルにしていません。普通のセル範囲のデータです。
|
B |
C |
D |
E |
F |
G |
H |
I |
| 2 |
番号 |
氏名 |
クラス |
年齢 |
性別 |
血液型 |
国語 |
数学 |
| 3 |
1 |
上原嘉男 |
B |
44 |
男 |
O |
91 |
55 |
| 4 |
2 |
森永彩芽 |
A |
58 |
女 |
A |
98 |
83 |
| 5 |
3 |
古田恵 |
B |
41 |
女 |
AB |
61 |
72 |
| 6 |
4 |
太田千恵子 |
B |
34 |
女 |
B |
46 |
48 |
| 7 |
5 |
豊田啓一 |
C |
38 |
男 |
O |
78 |
81 |
| 8 |
6 |
新村遥奈 |
C |
29 |
女 |
A |
76 |
61 |
| 9 |
7 |
坂元彩香 |
C |
38 |
女 |
AB |
68 |
83 |
| 10 |
8 |
坪井尚生 |
A |
45 |
男 |
A |
77 |
60 |
| 11 |
9 |
西原舞 |
A |
47 |
女 |
B |
41 |
77 |
| 12 |
10 |
中野野乃花 |
C |
51 |
女 |
O |
93 |
96 |
| 13 |
11 |
岩渕佳代 |
C |
44 |
女 |
A |
61 |
54 |
| 14 |
12 |
市村将文 |
A |
58 |
男 |
AB |
66 |
48 |
| 15 |
13 |
芦田公平 |
A |
59 |
男 |
A |
90 |
47 |
| 16 |
14 |
高見美姫 |
B |
34 |
女 |
AB |
81 |
97 |
| 17 |
15 |
高山晴彦 |
A |
65 |
男 |
B |
76 |
43 |
| 18 |
16 |
高島嘉子 |
B |
53 |
女 |
A |
85 |
93 |
| 19 |
17 |
蛭田功一 |
C |
46 |
男 |
O |
60 |
94 |
| 20 |
18 |
北奈那 |
B |
42 |
女 |
B |
84 |
71 |
| 21 |
19 |
本田明莉 |
A |
62 |
女 |
A |
66 |
71 |
| 22 |
20 |
東海林真依 |
B |
63 |
女 |
AB |
92 |
79 |
- K3セルの数式:=PIVOTBY(G2:G22,F2:F22,HSTACK(H2:H22,I2:I22),SUM,3,1,,0)
国語と数学の計算ができました。
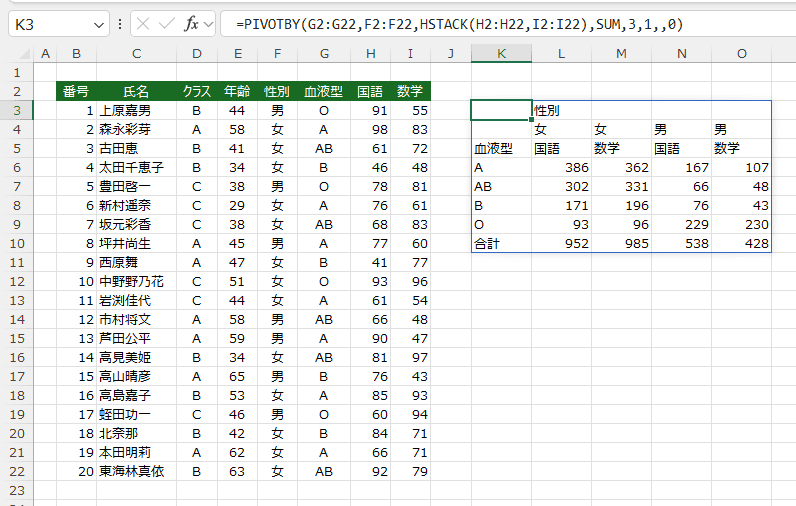
- 計算方法に合計 SUM と平均 AVERAGE を指定して、複数の計算を実行してみました。
ヘッダーの表示がちょっと気になってので、3と1の2種類を設定してみました。
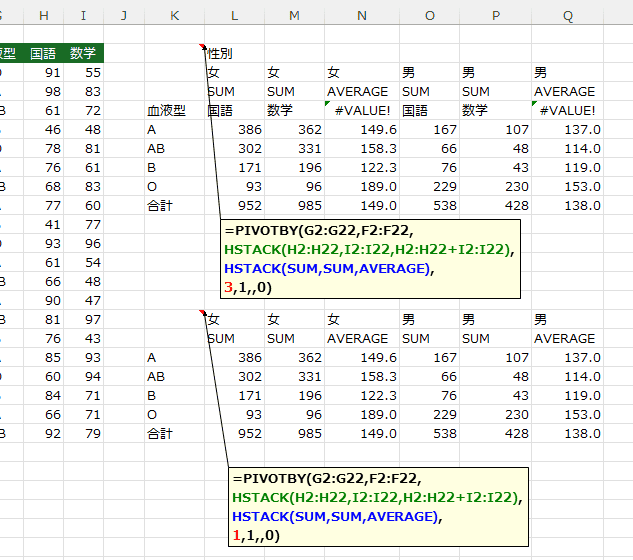
=PIVOTBY(G2:G22,F2:F22,
HSTACK(H2:H22,I2:I22,H2:H22+I2:I22),
HSTACK(SUM,SUM,AVERAGE),
3,1,,0)
=PIVOTBY(G2:G22,F2:F22,
HSTACK(H2:H22,I2:I22,H2:H22+I2:I22),
HSTACK(SUM,SUM,AVERAGE),
1,1,,0)
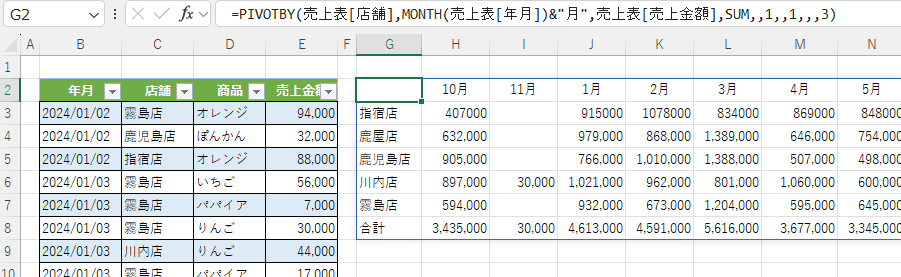
- 列データは年月日の日付が入力されていますが、MONTH(売上表[年月])として月ごとに計算することもできます。
=PIVOTBY(売上表[店舗],MONTH(売上表[年月])&"月",売上表[売上金額],SUM,,1,,1,,,3)
- Sheet1〜Sheet3にそれぞれ テーブル1〜テーブル3があります。
これらのデータをPivotBy関数で集計します。
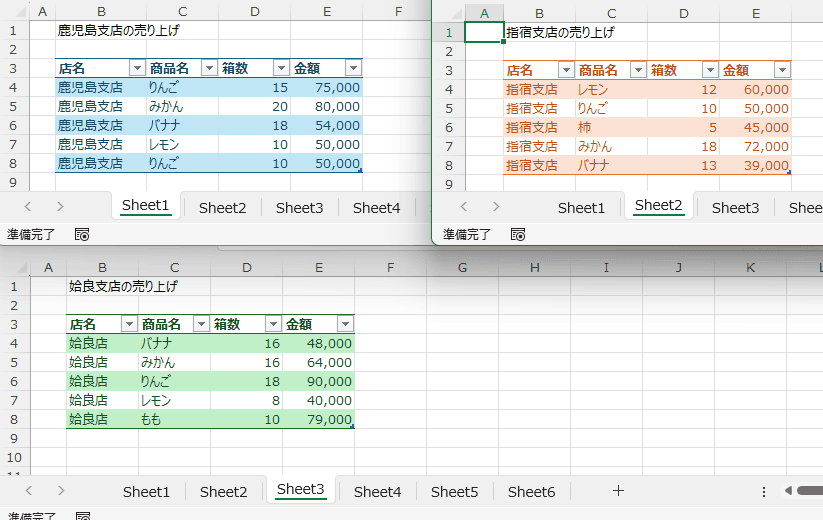
- E3セルには
=PIVOTBY(CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),2),
CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),1),
CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),4),
SUM)
と入力しています。
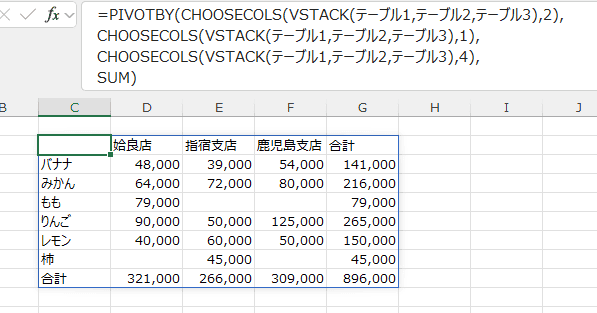
- VSTACK(テーブル1,テーブル2,テーブル3)
テーブル1〜テーブル3をVSTACK関数で縦に結合しています。
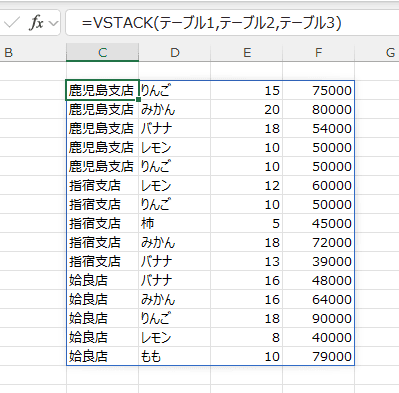
- CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),2)
行のデータに結合したデータの2列目をCHOOSECOLS関数で指定しています。

- CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),1)
列のデータに結合したデータの1列目をCHOOSECOLS関数で指定しています。

- CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),4)
値には結合したデータの4列目を指定しています。
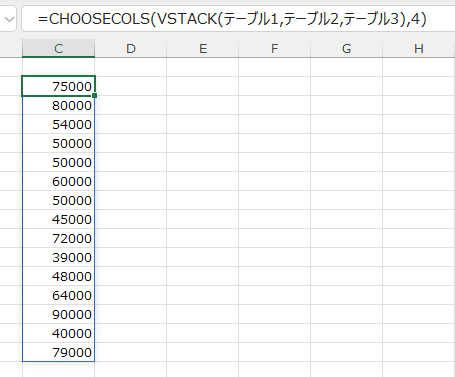
- 計算方法は SUM としています。
Home »
エクセル関数一覧表 » PIVOTBY関数でクロス集計表を作る
PageViewCounter
Since2006/2/27