- Home »
- エクセル関数一覧表 »
- Excel関数の目次 »
- GROUPBY関数を使って集計する
- SQL(データベース言語)の「GROUP BY」と似ていますが、このページではExcelの関数、GROUPBY関数について書いています。
- Excel for Microsoft 365 で使用することができるようになったGROUPBY関数の使い方を丁寧に説明しています。
引数の使い方も詳細に説明しています。
- 一つの列をグループ化して複数の関数で集計したり、複数の列をグループ化して複数の関数で処理することもできます。
クロス集計をしたい場合はPIVOTBY関数を使います。
更新:2024/12/05;作成:2024/10/29
グループ化して集計などの計算をする
グループ バイ
=GROUPBY(row_fields,values,function,
[field_headers],[total_depth],[sort_order],[filter_array],[field_relationship])
- GROUPBY関数がExcel for Microsoft 365 で使用することができるようになりました。(2024/10/29に確認しました)
現在のチャネルのリリース ノート(Microsoft 365)によると、バージョン 2409 (ビルド 18025.20096),バージョン 2409: 9 月 23 日から使用できるようになったようです。

- GROUPBY関数の引数(現時点では英語表記になっています。)
| 引数 |
|
意味 |
| row_fields |
必須 |
行のデータ |
| values |
必須 |
値 |
| function |
必須 |
関数 |
| field_headers |
省略可 |
ヘッダーの表示方法 |
| total_depth |
省略可 |
合計の表示方法 |
| sort_order |
省略可 |
並べ替え |
| filter_array |
省略可 |
フィルター |
| field_relationship |
省略可 |
リレーション |
- row_fields:行のデータはユニークなデータが昇順に並べられます。
複数の列を指定することもできます→列を入れ替えて計算する
- values:複数の列を指定することもできます→複数の関数(AVERAGEとSUM)で計算する
- イータ縮小ラムダ関数で指定します。明示的なLAMBDA関数で指定することもできます。
イータ縮小ラムダ関数「SUM」は、LAMBDA(x,SUM(x)) というLAMBDA関数式の簡略版です。
Helpには下表のように記されています。
値の集計に使用される、明示的または eta の縮小ラムダ (SUM、PERCENTOF、AVERAGE、COUNT など)。
ラムダのベクトルを指定できます。 その場合、出力には複数の集計が含まれます。 ベクターの向きによって、行方向と列方向のどちらをレイアウトするかが決まります。 |
SUBTOTAL関数のように数値で指定しません。またいくつかの関数が選択肢に増えています。
(PERCENTOF、ARRAYTOTEXT、MODE.SNGL、LAMBDA)
複数の計算方法を指定することもできます→複数の関数(AVERAGEとSUM)で計算する
| イータ縮小ラムダ関数 |
意味 |
| SUM |
合計値 |
| PERCENTOF |
構成比率 |
| AVERAGE |
平均値 |
| MEDIAN |
中央値 |
| COUNT |
値の件数 |
| COUNTA |
全ての件数 |
| MAX |
最大値 |
| MIN |
最小値 |
| PRODUCT |
掛けた値 |
| ARRAYTOTEXT |
文字を区切り文字付で結合する |
| CONCAT |
文字を結合する |
| STDEV.S |
標準偏差(標本) |
| STDEV.P |
標準偏差(母集団全体) |
| VAR.S |
分散(標本) |
| VAR,P |
分散(母集団全体) |
| MODE.SNGL |
最頻値 |
| LAMBDA |
任意の計算方法 |
- ここの数式をトレースできるようにデータをリストにしておきますので、ご利用ください。
| |
B |
C |
D |
E |
F |
G |
| 3 |
番号 |
氏名 |
年齢 |
性別 |
血液型 |
得点 |
| 4 |
1 |
上原嘉男 |
44 |
男 |
O |
91 |
| 5 |
2 |
森永彩芽 |
58 |
女 |
A |
98 |
| 6 |
3 |
古田恵 |
41 |
女 |
AB |
61 |
| 7 |
4 |
太田千恵子 |
34 |
女 |
B |
46 |
| 8 |
5 |
豊田啓一 |
38 |
男 |
O |
78 |
| 9 |
6 |
新村遥奈 |
29 |
女 |
A |
76 |
| 10 |
7 |
坂元彩香 |
38 |
女 |
AB |
68 |
| 11 |
8 |
坪井尚生 |
45 |
男 |
A |
77 |
| 12 |
9 |
西原舞 |
47 |
女 |
B |
41 |
| 13 |
10 |
中野野乃花 |
51 |
女 |
O |
93 |
| 14 |
11 |
岩渕佳代 |
44 |
女 |
A |
61 |
| 15 |
12 |
市村将文 |
58 |
男 |
AB |
66 |
| 16 |
13 |
芦田公平 |
59 |
男 |
A |
90 |
| 17 |
14 |
高見美姫 |
34 |
女 |
AB |
81 |
| 18 |
15 |
高山晴彦 |
65 |
男 |
B |
76 |
| 19 |
16 |
高島嘉子 |
53 |
女 |
A |
85 |
| 20 |
17 |
蛭田功一 |
46 |
男 |
O |
60 |
| 21 |
18 |
北奈那 |
42 |
女 |
B |
84 |
| 22 |
19 |
本田明莉 |
62 |
女 |
A |
66 |
| 23 |
20 |
東海林真依 |
63 |
女 |
AB |
92 |
- データは「成績表」というテーブルに変換しています。
計算方法に「SUM」を指定しました。
血液型ごとに得点が合計されています。
血液型のデータはユニークなデータが昇順に並べられています。
SORT関数,UNIQUE関数,SUMIF関数での計算が一気にできた感じです。
=GROUPBY(成績表[血液型],成績表[得点],SUM,0,0)
- 引数:field_headers:ヘッダーを表示しない、total_depth:合計を表示しない
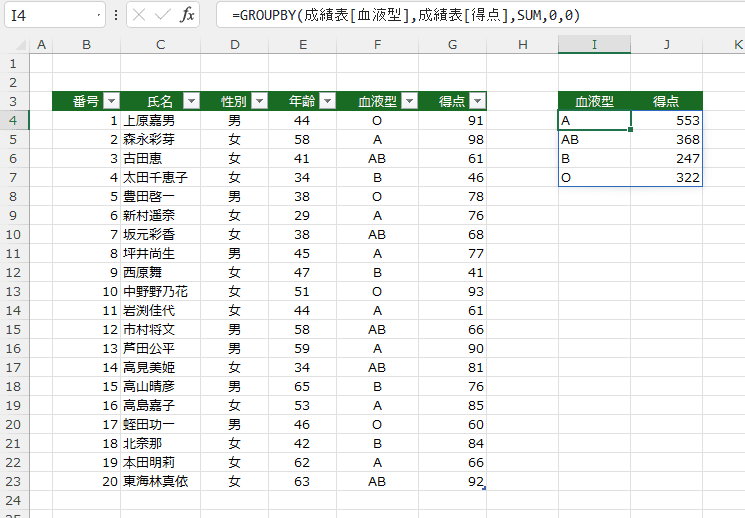
- イータ縮小ラムダ関数 SUM を明示的なLAMBDA関数 LAMBDA(x,SUM(x)) で指定すると、下図のようになります。
=GROUPBY(成績表[血液型],成績表[得点],LAMBDA(x,SUM(x)),0,0)
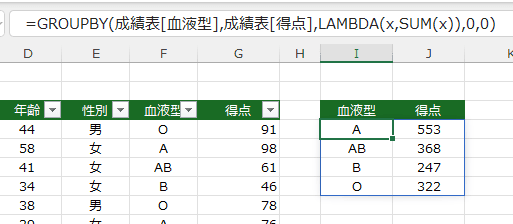
- GROUPBY関数が使えないExcel2021では、
L3セルに =SORT(UNIQUE(成績表[血液型]))
M3セルに =SUMIF(成績表[血液型],L4#,成績表[得点])
と計算することができます。
- 引数の「field_headers:ヘッダーの表示方法」には下表の設定ができます。
| 引数 |
意味 |
| 0 |
フィールドにフィールド名がないので、表示しない |
| 1 |
フィールドにフィールド名が含まれているが、表示しません |
| 2 |
フィールドにフィールド名がないので、生成しない?
(実際は、Excelが勝手にヘッダーを表示します) |
| 3 |
フィールドにフィールド名が含まれているので、表示します |
- 血液型ごとに得点が合計されています。データは「成績表」というテーブルに変換しています。
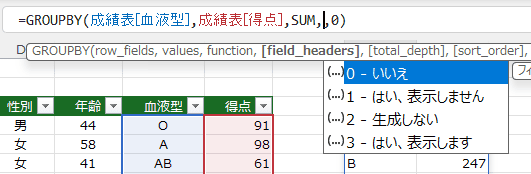
- テーブルの場合は、フィールド名は含まれていないので、0と2が設定できます。
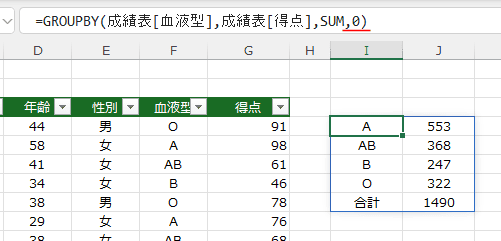
2 を指定した場合は 「行フィールド1」「値1」と表示されました。
Excelが勝手に生成する?ということかも?
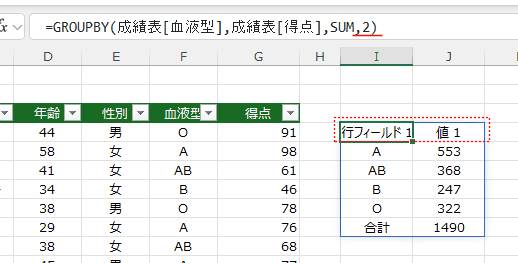
- テーブルの場合は、フィールド名は含まれていないので、1を指定すると、フィールド名は表示されません。
0を指定するのと同じなので1を指定する意味はないといえそうです。
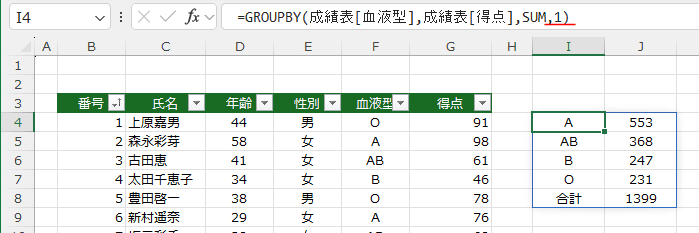
3を指定すると、データの1つ目がフィールド名とみなされて表示されてしまいます。
テーブルの場合は 3は指定してはいけません。
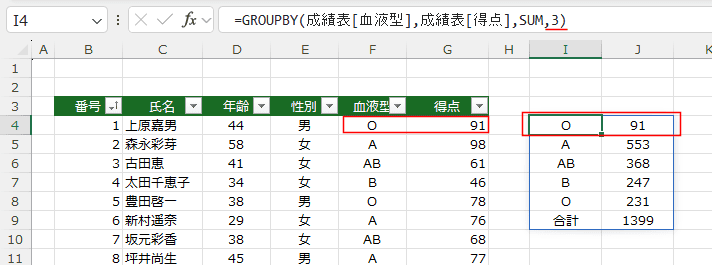
- データ範囲にフィールド名がある場合は1と3を指定します。
1を指定すると、ヘッダーは表示されません。
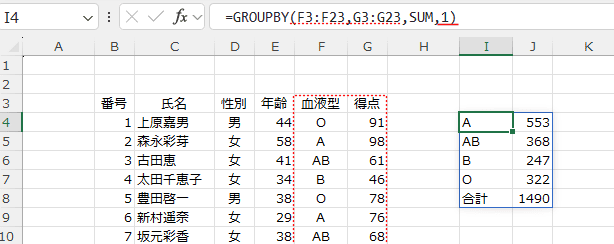
3を指定すると、データ範囲に含まれるフィールド名が表示されます。
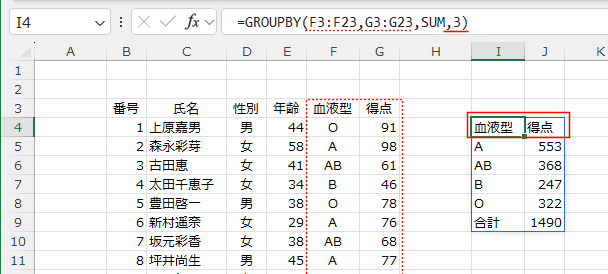
- データ範囲にフィールド名がない場合は0と2を指定します。
0を表示すると、フィールド名(ヘッダー)は表示されません。
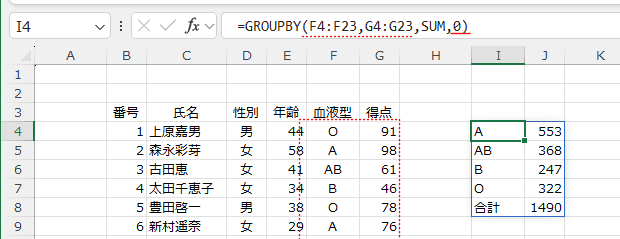
2を指定すると、「行フィールド1」「値1」と表示されました。
Excelが勝手に生成する?ということかも?
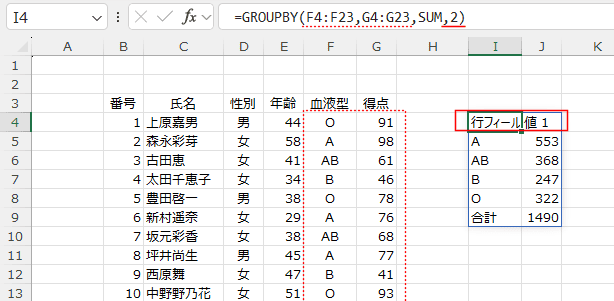
- MicrosoftのHelpに下記のような注意事項が書いてあります。
Automatic は、値引数に基づいてデータにヘッダーが含まれていると想定します。
1 番目の値が text で、2 番目の値が数値の場合、データにはヘッダーがあると見なされます。
複数の行または列グループ レベルがある場合、フィールド ヘッダーが表示されます。 |
- 引数のtotal_depth:合計の表示方法 には下表の設定ができます。
省略すると、総計が表示されます。
| 引数 |
意味 |
| 0 |
合計なし |
| 1 |
総計 |
| 2 |
総計と小計 |
| -1 |
上部に総計 |
| -2 |
上部に総計と小計 |
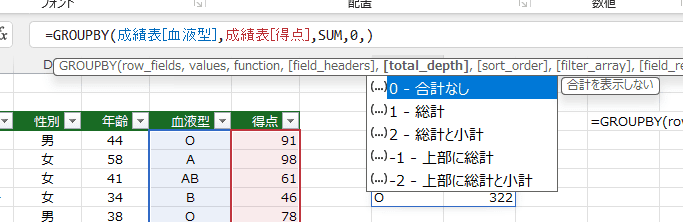
- 0-合計なし の場合は合計は表示されません。
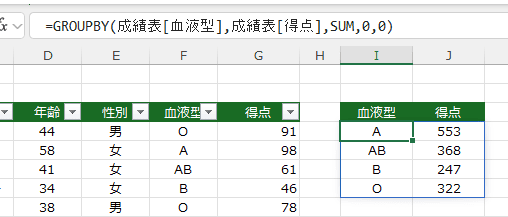
- 1-総計 の場合は合計が表示されました。
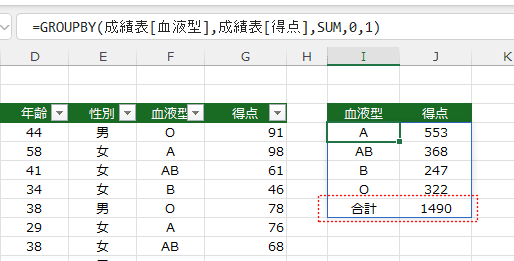
- 2-総計と小計 小計と総計が表示されます。
ここでは、2つの列でグループ化しています。1つの列では小計が計算できませんので、#VALUE! エラーとなります。
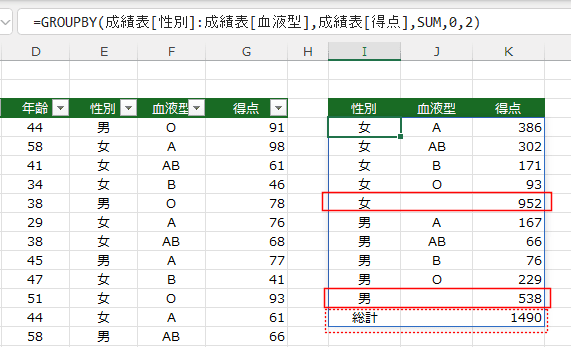
- -1-上部に総計 の場合は上部に合計が表示されます。
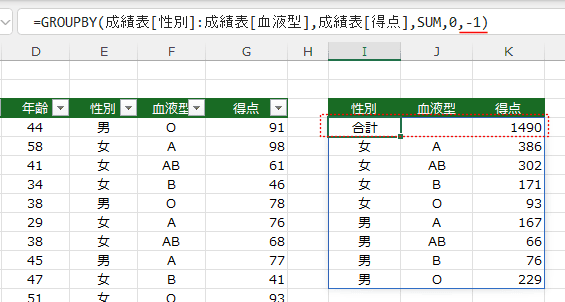
- -2-上部に総計と小計 の場合は 小計と総計が上部に表示されます。
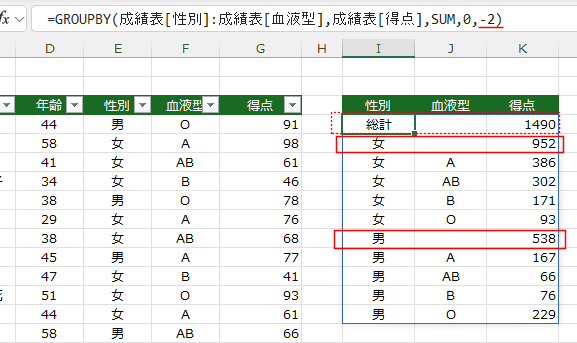
- MicrosoftのHelpに下記のような注意事項が書いてあります。
小計の場合、 フィールド には少なくとも 2 つの列が必要です。
フィールドに十分な 列がある場合、2 を超える数値がサポートされます。 |
- 引数は列の位置を指定します。
昇順は正の値、降順は負の値で指定します。
- 並べ替えは列の場所を指定します
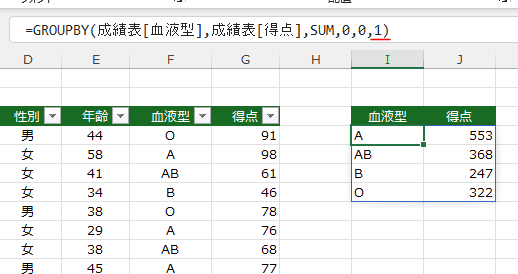
=GROUPBY(成績表[血液型],成績表[得点],SUM,0,0,1)
ここでは 1 を指定していますので、
血液型が昇順に並べ替えられました。
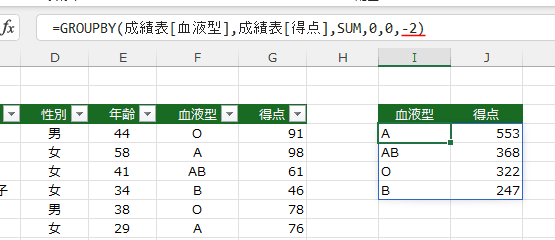
- この例では -2 としています。
2列目の得点を並べ替えますが、マイナスをつけていますので、降順に並べ替えます。
=GROUPBY(成績表[血液型],成績表[得点],SUM,0,0,-2)
- 複数の列を並べ替えることもできます。
=GROUPBY(成績表[性別]:成績表[血液型],成績表[得点],SUM,0,0,{-1,2})
性別の列が1でこの列は降順(-1:負の値)にしています。
血液型のれつが2でこの列は昇順(2:正の値)にしています。
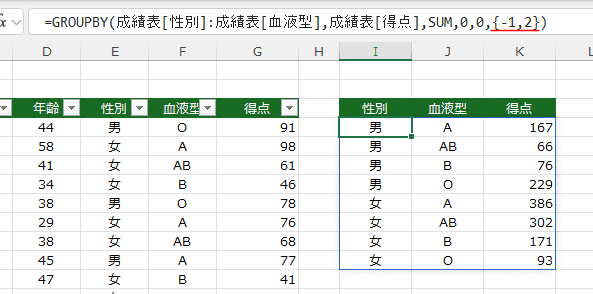
- データをフィルターして計算します。
=GROUPBY(成績表[血液型],成績表[得点],SUM,0,0,,成績表[血液型]="O")
成績表[血液型]="O" のデータだけが表示されました。

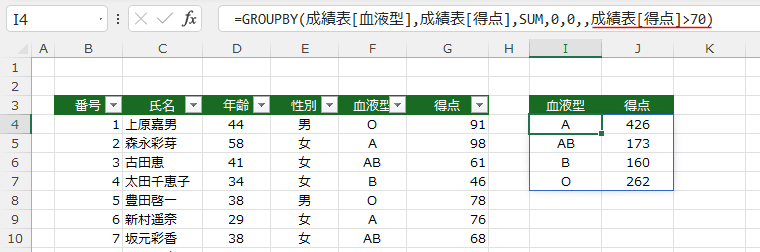
- 得点が70より大きいデータだけの合計を求めてみました。
=GROUPBY(成績表[血液型],成績表[得点],SUM,0,0,,成績表[得点]>70)
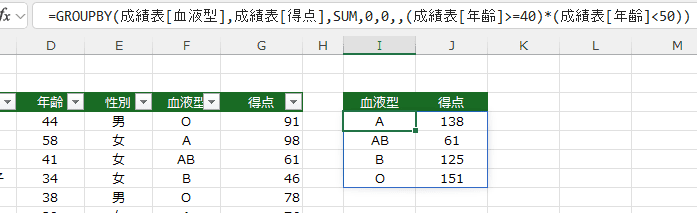
- 40才代の人の血液型別合計得点を求めてみます。
40以上、50未満 という条件を(成績表[年齢]>=40)*(成績表[年齢]<50)としました。
=GROUPBY(成績表[血液型],成績表[得点],SUM,0,0,,(成績表[年齢]>=40)*(成績表[年齢]<50))
- field_relationship:リレーション では0-階層(規定) と1-テーブルが指定できます。
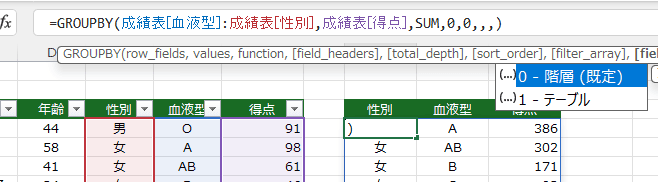
- どのような機能なのか今一つ理解できていないので、0-階層 を指定した例を示します。
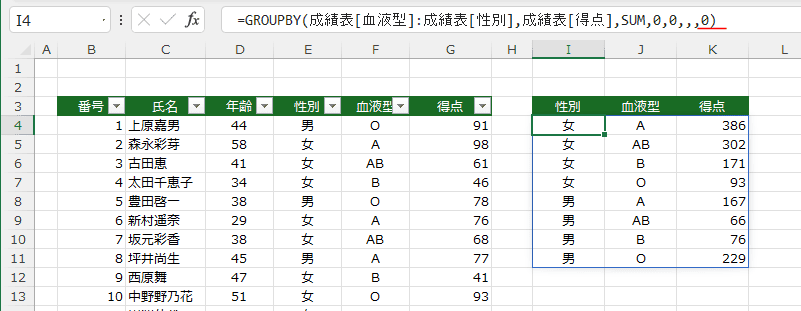
- 隣接した列を指定するのは何ら問題がないのですが、離れた列や順番を入れ替えたいときはほかの関数を利用します。
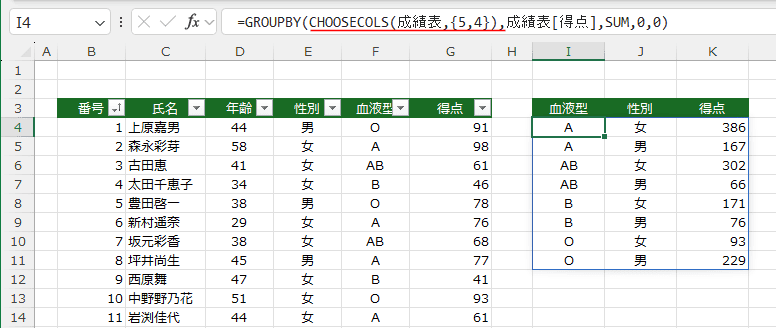
CHOOSECOLS関数やHSTCK関数を利用します。
- テーブル「成績表」では性別、血液型の順番になっています。
ここでは血液型。性別の順番に入れ替えたいと思います。
- =GROUPBY(CHOOSECOLS(成績表,{5,4}),成績表[得点],SUM,0,0)
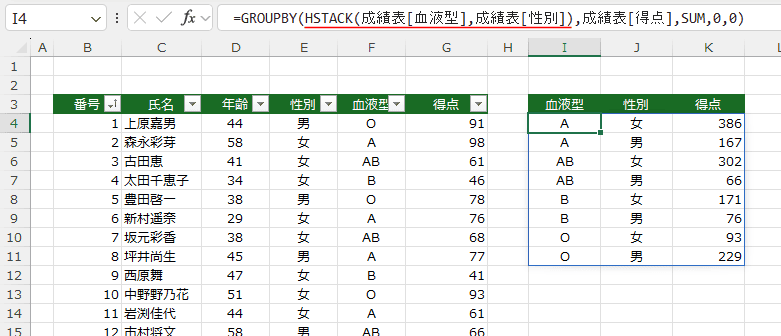
- =GROUPBY(HSTACK(成績表[血液型],成績表[性別]),成績表[得点],SUM,0,0)
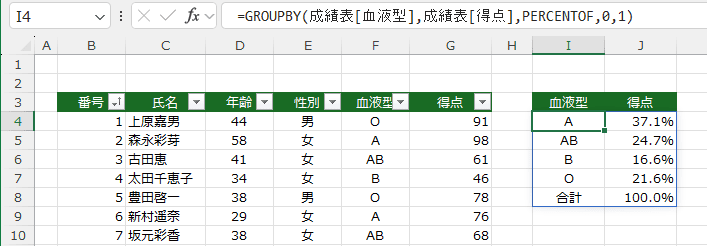
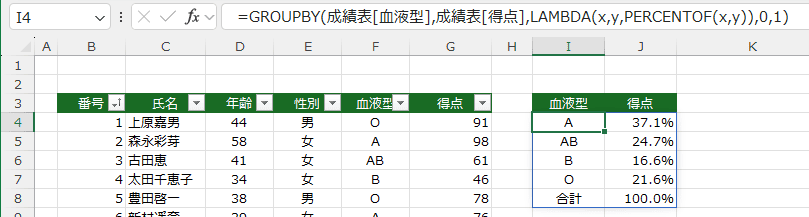
- 計算方法にイータ縮小ラムダ関数 PERCENTOF を指定した例です。
=GROUPBY(成績表[血液型],成績表[得点],PERCENTOF,0,1)
- 明示的なLAMBDA関数 LAMBDA(x,y,PERCENTOF(x,y)) で指定した例です。
=GROUPBY(成績表[血液型],成績表[得点],LAMBDA(x,y,PERCENTOF(x,y)),0,1)
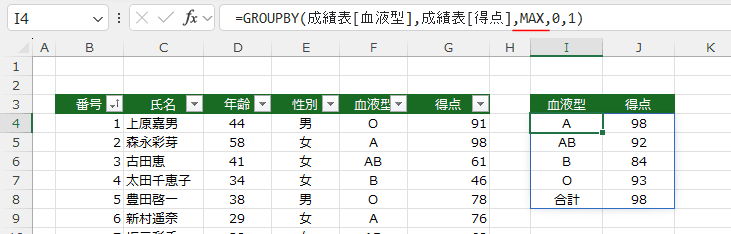
- 計算方法にイータ縮小ラムダ関数 MAX を指定した例です。
=GROUPBY(成績表[血液型],成績表[得点],MAX,0,1)
合計欄には最大値が表示されています。「合計」はちょっと違和感があります・・・。
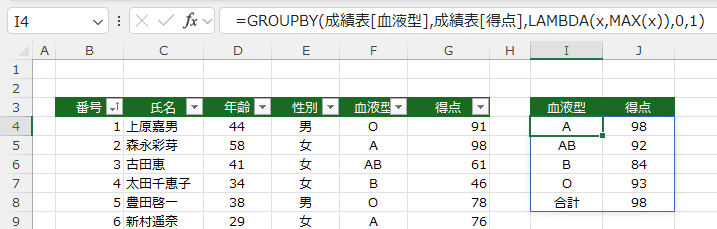
- 明示的なLAMBDA関数 LAMBDA(x,MAX(x)) を指定した例です。
=GROUPBY(成績表[血液型],成績表[得点],LAMBDA(x,MAX(x)),0,1)
計算する列が1列で計算方法が異なる計算を行う(AVERAGEとSUM)
- 複数の列を異なる集計方法で計算することもできます。
ちょっと煩わしい感じですが・・・こんなことも可能です。
ここではテーブルの名前は「成績表W」としています。
- 計算方法にAVERAGE,SUMの2つを指定しています。
引数の値は 成績表W[得点] の一つの列になっています。
つまり、得点の平均値と合計点を計算して表示しています。
HSTACK関数を使うと複数列に表示され、VSTACK関数を使うと複数行に表示されます。
- =GROUPBY(成績表W[血液型],
成績表W[得点],
HSTACK(AVERAGE,SUM))
- =GROUPBY(成績表W[血液型],
成績表W[得点],
VSTACK(AVERAGE,SUM))

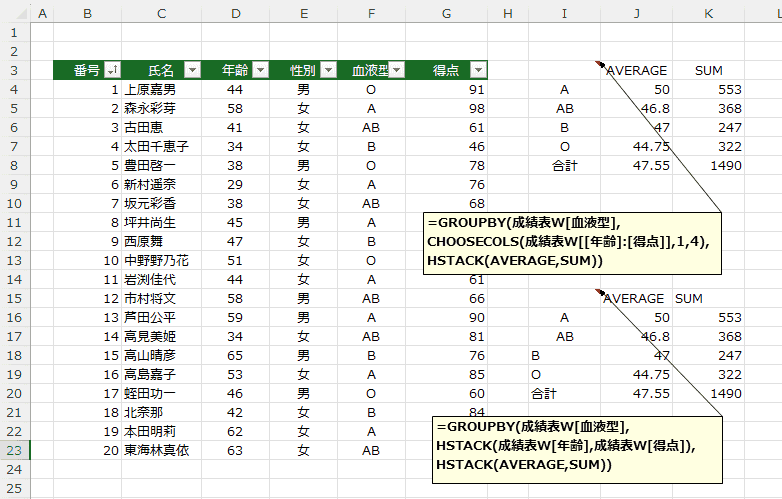
計算する列が2列で計算方法が異なる計算を行う(AVERAGEとSUM)
- こんどは、計算する列を2つにした例です。、
CHOOSECOLS(成績表W[[年齢]:[得点]],1,4)
と
HSTACK(成績表W[年齢],成績表W[得点])
のどちらでもよさそうです。
- =GROUPBY(成績表W[血液型],
CHOOSECOLS(成績表W[[年齢]:[得点]],1,4),
HSTACK(AVERAGE,SUM))
- =GROUPBY(成績表W[血液型],
HSTACK(成績表W[年齢],成績表W[得点]),
HSTACK(AVERAGE,SUM))
年齢の平均値と、得点の合計値が計算されています。
- テーブルを範囲に変換して、ヘッダーの表示方法の3を指定すると、わかりやすい表示になります。
範囲の指定時にフィールド名を含めて指定します。
=GROUPBY(F3:F23,
HSTACK(D3:D23,G3:G23),
HSTACK(AVERAGE,SUM),3)
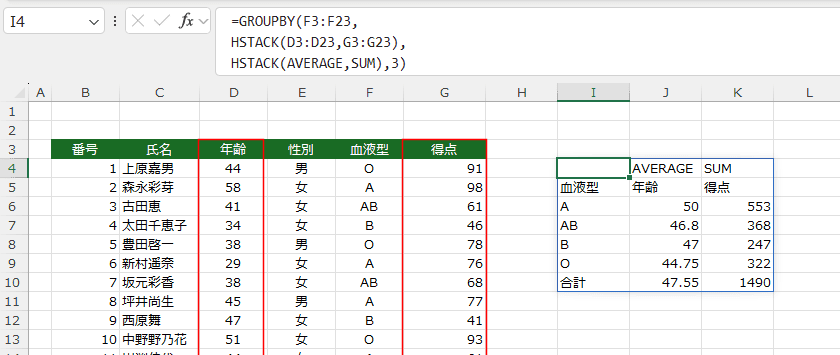
計算する列が3列で計算方法が異なる計算を行う(AVERAGEとAVERAGEとCOUNT)
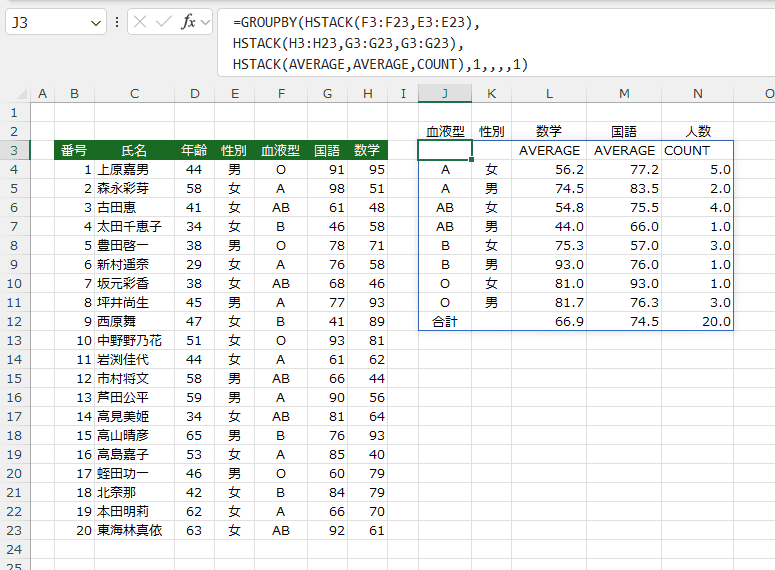
- このようなこともできます。
行のデータに2列、値に3つ指定し、計算方法に3つ指定しています。
列のフィールド名(J2:N2)は手入力しています。
J3セルには以下の数式を入力しています。
=GROUPBY(HSTACK(F3:F23,E3:E23),
HSTACK(H3:H23,G3:G23,G3:G23),
HSTACK(AVERAGE,AVERAGE,COUNT),1,,,,1)
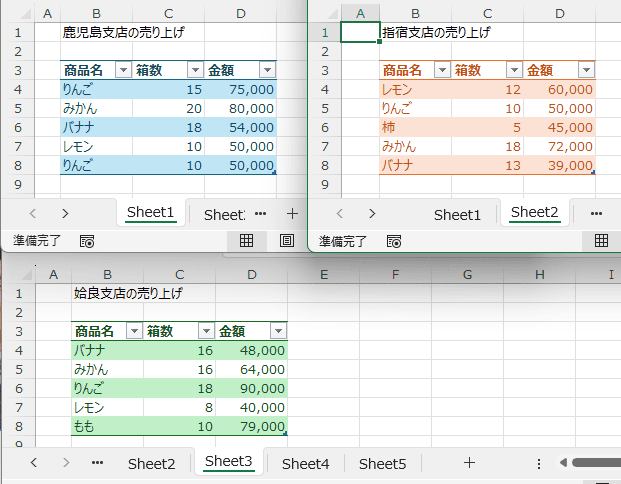
- Sheet1〜Sheet3のデータを集計することもできます。
ピボットテーブルや統合機能を使って集計することができましたが、GroupBy関数で簡単に複数シートを集計することができます。
- Sheet1〜Sheet3にそれぞれ テーブル1〜テーブル3があります。
これらのデータをGroupBy関数で集計します。
- 列のフィールド名(E2:G2)は入力しています。
E3セルには
=GROUPBY(CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),1),
CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),{2,3}),
SUM)
と入力しています。
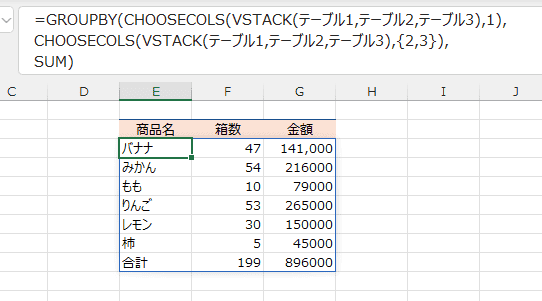
- VSTACK(テーブル1,テーブル2,テーブル3)
テーブル1〜テーブル3をVSTACK関数で縦に結合しています。
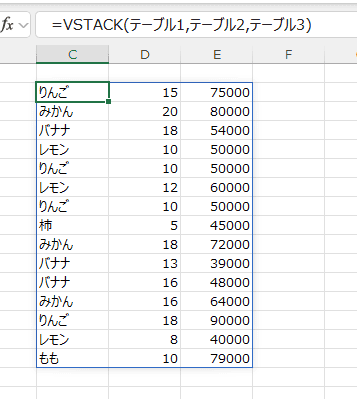
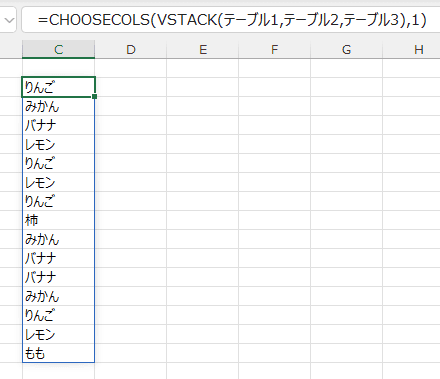
- CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),1)
行のデータに結合したデータの1列目をCHOOSECOLS関数で指定しています。
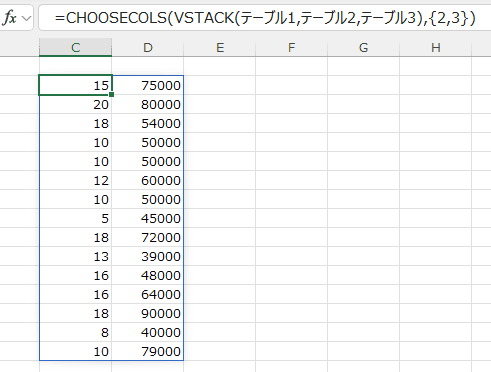
- CHOOSECOLS(VSTACK(テーブル1,テーブル2,テーブル3),{2,3})
値には結合したデータの2列目と3列目を指定しています。
- 計算方法は SUM としています。
Home »
エクセル関数一覧表 » GROUPBY関数を使って集計する
PageViewCounter
Since2006/2/27